Well, it happened again. I was just writing a UI system in C (different story) and thought about the performance of different ways to render rectangles. Most people would just look around a bit and choose a suitably impressive or "modern" approach and be done with it. Some would even research the topic for a bit and then choose the appropriate approach for their environment. Well, I did a bit of both, got distracted for a few weeks and somehow ended up with another small benchmark about UI rectangle rendering… I didn't do it on purpose! It just happened! Could happen to anybody, right? Ok… maybe there was a bit of purpose involved. :D
Aaanyway, most UIs today don't generate the pixels you see on screen directly. Instead they create a list of what needs to be drawn and then tell the GPU to do it. I wanted to know how long that GPU rendering part takes. Given the UI for a text editor, does it take 10ms, 1ms or 0.1ms? After all, everything before that point depends on how I choose to design the UI system. But I can't choose to create a graphical user interface that doesn't show anything. So that rendering part is my hard performance limit and I can't get faster than that.
TLDR: On a desktop system it takes between 1ms and 0.1ms to render a text editor UI with a lot of characters (6400 mostly small rects). At least when rendering is done using one large buffer for rectangle data and one draw call. ~1ms on low-end systems (AMD A10-7850K Radeon R7 and i7-8550U with UHD 620) and ~0.1ms on more decent GPUs (Radeon RX 480, Arc A770, GeForce GTX 1080).
Results (without context)
In case you just want to dive in, here are the results for a text editor and mediaplayer dummy UI. Those charts are huge, you have been warned:


Yes, you'll have to scroll around a lot. Those two images contain the measured times for different approaches (on the left) on different hardware (on the top).
I was also interested in how the different approaches compare to one another on the same hardware. Basically which approach I should use for my UI system. So here are the same diagrams but normalized to the one_ssbo_ext_one_sdf approach. Meaning that the values for one_ssbo_ext_one_sdf are always 1.0. But if e.g. the draw calls of ssbo_instr_list take 3 times longer on the GPU that bar would now show a 3.00. Note that the visual bars are capped at 5.0, otherwise the diagram would be mindbogglingly huge.


Please don't use the data to argue that one GPU is better than another. Rectangle rendering is a trivial usecase compared to games and the workload is very different. The first set of charts is there to get a rough feeling for how long it takes to render a UI, the second set of chars to compare the approaches with each other.
I've put the raw data and source code into a repository. Take a look if you want, but be warned, this is a hobby project. The code is pretty ugly and there's a lot of data. I don't get paid enough for that to think about how other programmers read the source code of my crazy experiments.
Context (aka what all that means)
My target systems were linux and windows desktops. No smartphones, no tables, no Macs. Mostly because developing for them is a pain and at that point I'm doing this for fun.
I used OpenGL 4.5 as an API. It's well supported on Linux and Windows and the Direct State Access API makes it quite pleasant to work with (no more binding stuff). I though about using Vulkan but it would be a lot more hassle and when I made that decision there was no Mesa driver for nVidia hardware (I'm using an AMD GPU but I didn't want to close off that option). Mac only supports OpenGL 4.3, but I don't care about that system either.
UI scenarios
There are 2 dummy UI scenarios. Both look like crap because this isn't about the quality of font rendering, etc. I just wanted to get somewhat realistic lists of rectangles and textures.
sublime
scenario, 6400 rectangles with an average area of 519px². Mostly small glyph rectangles but also some larger ones (window, sidebar, etc.) that push up the average.
mediaplayer
scenario, 53 rects with an average area of 55037px². Not a lot of text, hence the bigger rectangles dominate.
Both scenarios are pretty extreme cases. sublime has a lot of small textured rectangles that show glyphs, meaning more load on vertex shaders. mediaplayer has a lot fewer rects where the larger ones really dominate, resulting in more load on fragment shaders. I figured most real UIs would be somewhere in between those two extremes.
Btw. that image in the mediaplayer is Clouds Battle by arsenixc. I just wanted something interesting to look at during development.
Measurement and benchmark procedure
From a measurement perspective each approach basically looks like this:
Benchmarked stages of the rendering process
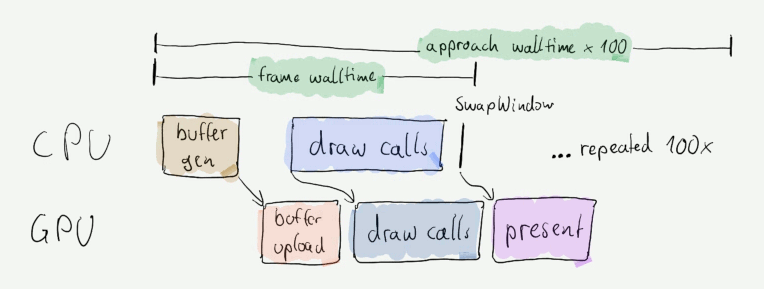
For each of those stages I measured different things:
- CPU walltime, measured with
gettimeofday().
- Consumed CPU time of the process, measured with
clock_gettime() (Linux) and GetProcessTimes() (Windows).
- GPU elapsed time, measured with
glBeginQuery(GL_TIME_ELAPSED, …) and glEndQuery(GL_TIME_ELAPSED).
- GPU timestamps with
glQueryCounter(…, GL_TIMESTAMP).
The GPU times are read after each frame so there is a pipeline stall there. I was to lazy to use multiple buffers for that. Also GL_TIME_ELAPSED timers seem to have a lot better resolution, so those in the benchmark results above. If something takes 100µs (that's thousands of a millisecond) it doesn't really matter, e.g. 111.200µs GL_TIMESTAMP vs. 107.680µs GL_TIME_ELAPSED. But for very short operations it can differ drastically: 3.840µs GL_TIMESTAMP vs. 0.640µs GL_TIME_ELAPSED. That was on a Radeon RX 480 on Linux (Mesa driver) and the Intel Arc A770 on Windows looks similar. On a GeForce GTX 1080 the difference wasn't quite so drastic (2.048µs GL_TIMESTAMP vs. 1.024µs GL_TIME_ELAPSED) but the resolution seems to be just a 10th of the other cards.
Measuring the consumed CPU time was a similar problem. That is the CPU time all threads in the entire process consumed. I wanted to know that to catch any processing that doesn't happen during the frame (driver overhead, pipelined drivers, etc.) and it's generally a nice indicator of how costly a given approach is on the CPU in total. Unfortunately on Windows the resolution of GetProcessTimes() isn't good enough to do that each frame. A lot of the values simply came out as 0 for most frames. Linux doesn't have that problem.
My workaround was to measure the walltime and consumed CPU time for 100 frames and divide it by 100. Unfortunately this includes the benchmarking code itself, which does some pretty hefty printf() calls to log the data. But that is the same overhead for all approaches. So if one approach consumes 40 times more CPU time than another (I kid you not) it's pretty inefficient, benchmarking overhead or not.
Dumping all that data into a bar chart would be useless, so the result charts only show the interesting measurements. Those are also depicted in the stage diagram above. And yet the result chars are still pretty unwieldy. :(
- Approach walltime (with overhead): The CPU walltime to render 100 frames with a given approach, including the time it took to measure and log the data. Then divided by 100 to get an average per-frame time.
- Approach CPU time (with overhead): Consumed CPU time of all threads in the process to render 100 frames. Again including the benchmarking overhead, again divided by 100.
- Frame CPU walltime: The CPU walltime from the start of the frame until after the call of
SDL_GL_SwapWindow(). Pretty much how long the CPU takes to tell the GPU what to do. This does not include the pipeline stall to read the GPU times (but maybe SDL_GL_SwapWindow() does a pipeline stall, I don't know).
- Buffer generation CPU walltime: Almost all approaches need to prepare one large buffer with all the rectangle data for the GPU. This is how long the CPU takes for only that stage.
- Buffer upload GPU elapsed time: GPU time spend to transfer the rectangle buffer from the CPU memory into GPU memory. Measured with
GL_TIME_ELAPSED.
- Draw calls CPU walltime: CPU walltime spend to call the OpenGL draw calls. Basically how expensive it is to tell the OpenGL driver what we want from it.
- Draw calls GPU elapsed time: GPU time spend actually executing those draw calls on the GPU. This is how expensive the operation actually is for the hardware. Measured with
GL_TIME_ELAPSED.
- Present GPU elapsed time: The GPU time spend in
SDL_GL_SwapWindow(), whatever that is. I hope it's just the driver handing off the rendered frame to the window manager or DWM. But I added it to catch drivers that defer some work into that stage. Not sure what to make of the measurements, though. On Linux it's pretty much nothing, on Windows it can sometimes take longer than the rectangle rendering itself.
The benchmark itself simply runs every approach, each one rendering 100 frames without vsync. The benchmark program is then run 5 times in a row. Sometimes it's just slower, maybe because the benchmark starts on an unlucky core or something. Hence the 5 repeats. The average of those 500 samples is then taken to get the per-frame values in the result charts. Except for "approach walltime" and "approach CPU time", there it's just an average of 5 values divided by 100.
Thanks to my brother we could run the benchmark on a lot of different systems. He has quite a lot of different hardware and that way I got data for the Intel Arc A770 GPU, older and newer nVidia GPUs and a lot of different AMD GPUs. :)
Approaches
Now we're on to the meat of the thing.
The approaches I implemented are a somewhat random mishmash of ideas. No all approaches do the same. Some just implement basic textured rectangles while others offer more complex rendering features (like signed distance fields, rounded corners, etc.). That was just my laziness and the observation that it doesn't make that much of an impact and my data is pretty noisy anyway. Remember, I'm doing that just for fun.
I'll compare most approaches to the one_ssbo_ext_one_sdf approach. That was the most promising one when I had the idea to normalize the data, so it became the reference point.
For details feel free to look into 26-bench-rect-drawing.c. Again, be warned, this is ugly code. ;)
1rect_1draw
One draw call per rectangle. The rectangle data is set via uniforms and no buffer is needed. But that approach it pretty much maximum API overhead personified. Doesn't make much sense, but I wanted to see how spectacular the fireball is. Implemented textured rectangles, colored glyphs and rounded rectangles with borders for that one.
In the mediaplayer scenario with it's 53 rects it doesn't really matter. It consumes a bit more "Draw calls CPU walltime" but that's it. This scenario performs similarly for pretty much all approaches, so from here on out I'll only talk about the sublime scenario.
That one has 6400 rects and this approach just dies, with frame CPU walltimes being 20x to almost 40x slower than one_ssbo_ext_one_sdf (but on one slow system it was just 2x slower). The draw calls CPU walltime explodes even more spectacularly, mostly being a few hundred times slower than one_ssbo_ext_one_sdf. Now that is API overhead. :D
To put it into somewhat real numbers, on my Radeon RX 480 Linux system this means the following (1rect_1draw vs. one_ssbo_ext_one_sdf):
Frame CPU walltime: 3.699ms vs. 0.095ms
Draw calls CPU walltime: 3.651ms vs. 0.004ms
Draw calls GPU elapsed time: 0.236ms vs. 0.142ms
complete_vbo
The simplest "classic" way to render rectangles with one large vertex buffer in OpenGL. Six vertices per rectangle (2 triangles, each 3 vertices) with the per-rectangle data duplicated in each vertex. A vertex array object (VAO) and vertex attributes are setup to feed the buffer into the vertex shader. Again implemented textured rectangles, colored glyphs and rounded rectangles with borders.
Buffer generation CPU walltime is mostly 3 to 4 times slower than one_ssbo_ext_one_sdf which is no surprise. It generates pretty much 6 times as much data because one_ssbo_ext_one_sdf just uses a list of rectangles instead of vertices. Frame CPU walltime is mostly 2x that of one_ssbo_ext_one_sdf.
And in numbers on my Radeon RX 480 Linux system (complete_vbo vs. one_ssbo_ext_one_sdf):
Frame CPU walltime: 0.340ms vs. 0.095ms
Buffer generation CPU walltime: 0.123ms vs 0.032ms
Draw calls CPU walltime: 0.004ms vs. 0.004ms
Draw calls GPU elapsed time: 0.254ms vs. 0.142ms
one_ssbo
That approach was inspired by how compute shaders read their input (a more "modern" approach). It uses one shader storage buffer object (SSBO) with a list of rectangle data. An empty VAO is setup without any vertex attributes, so no data is fed into the vertex shader by OpenGL. But each shader can access the SSBO. Then 6 vertex shaders per rectangle are spawned, each shader uses the gl_VertexID to calculate the index of the rectangle it belongs to, reads the rectangle data and puts itself on the proper screen position.
This bypasses the whole VAO and vertex attribute mess of the OpenGL API, which is nice. But on the flip side we can only read uints, floats, vec4s and stuff. Not single bytes. So we have to unpack 8bit values from 32bit (e.g. colors) via bitshifts and bitmasks or bitfieldExtract() or unpackUnorm4x8().
Again implemented textured rectangles, colored glyphs and rounded rectangles with borders.
This one is usually about as fast as one_ssbo_ext_one_sdf. Sometimes a bit faster, sometimes a bit slower. The draw calls GPU elapsed time is usually a bit on the faster side but one_ssbo_ext_one_sdf can do more complex rendering so this is to be expected.
On my Radeon RX 480 Linux system:
Frame CPU walltime: 0.084ms vs. 0.095ms
Buffer generation CPU walltime: 0.025ms vs 0.032ms
Draw calls CPU walltime: 0.004ms vs. 0.004ms
Draw calls GPU elapsed time: 0.137ms vs. 0.142ms
All in all a pretty robust approach. Works well and is fast on pretty much any system the benchmark was run on, but I hope you like bit twiddling and memory layouts. ;)
ssbo_instr_list
This approach also uses one SSBO to store the rectangle data. But what kind of processing the fragment shader should do is stored in a second "instruction list" SSBO. For example if you just want to render a glyph there would be one entry in the rect list and one glyph rendering instruction for that rect in the instruction list. If you want to render a rounded rect with two borders you can do that with 3 instructions.
This makes each entry in the rect list smaller since it doesn't need to contain the data for all possible rendering features. Each instruction was also packed into 64 bit, making them fairly small. But the primary idea behind that approach was flexibility. I added instructions for different kinds of signed distance fields (rounded rect, circle, lines, etc.) and wanted to combine them with border drawing, drop shadow drawing and so on. And you would only have to pay that memory and processing cost for rects that actually use those instructions. Again, inspired by how you would do it with compute shaders. Sounds nice, doesn't it?
The frame CPU walltime is mostly a bit faster than one_ssbo_ext_one_sdf. But for draw calls GPU elapsed time it depends. AMD mostly agrees with that approach. There the GPU time is roughly about as fast as one_ssbo_ext_one_sdf. Sometimes it just takes 0.6 times, sometimes 2.0 times as much GPU time. nVidia and Intel disagree. :( On nVidia it takes about 2.0 times as much GPU time, on Intel 3 to 4 times. Seems like they really don't like that the fragment shader reads a variable number of instructions, even if most rects just read one (glyph instruction).
On my Radeon RX 480 Linux system (funnily enough on Windows this approach was twice as fast):
Frame CPU walltime: 0.136ms vs. 0.095ms
Buffer generation CPU walltime: 0.019ms vs 0.032ms
Draw calls CPU walltime: 0.004ms vs. 0.004ms
Draw calls GPU elapsed time: 0.288ms vs. 0.142ms
So this approach offers great flexibility, seems to be about as fast as one_ssbo_ext_one_sdf from the CPUs point of view but stresses Intel and nVidia GPUs a lot more.
ssbo_inlined_instr_6
Well, what if we read those processing instructions in the vertex shader instead of the fragment shader? That way each rect would only read the instructions 6 times from GPU global memory (once for each vertex). Of course we then need to transfer those instructions from the vertex shaders to the fragment shaders. In this case I used an uvec2[6] array, aka 6 64 bit values. This limits the flexibility somewhat, but with 6 instructions you can do a lot of fancy stuff (e.g. drawing a rounded rect with 5 different borders).
AMD and Intel GPUs like it. For those it usually takes ~1.1 times (AMD) or ~1.5 times (Intel) as much GPU time as one_ssbo_ext_one_sdf. Still not great, but think about the flexibility those instructions allow! :) Well, nVidia just says no. They take 3 to 4 times as much GPU time. :(
At that point I was very tempted to just ignore nVidia GPUs. They have how knows how many engineers and enough marketing people to tell the world 10 times over how great their GPUs are. Then I should not have to worry about iterating over an instruction list in the fragment shader. Maybe it's the data transfer from vertex to fragment shader (but other approaches use more and are a lot faster), the bit unpacking in the fragment shader, maybe its just the instruction loop, I don't know. In case anyone has an idea feel free to look at the source code.
Then, grudgingly, my professional attitude came back in. I wanted to see what works well on every GPU… well, the instruction list doesn't. :(
one_ssbo_ext_one_sdf
This is basically back to one_ssbo but extended to support more fancy shapes within a rectangle. That works via signed distance functions to draw rounded rects, pie segments, polygons, etc. However it's limited to one fancy shape per rect, one border, etc. No more instruction list in there.
It works reasonable well on all GPUs, hence it became the reference point to compare the approaches.
On my Radeon RX 480 Linux system:
Frame CPU walltime: 0.095ms
Buffer generation CPU walltime: 0.032ms
Draw calls CPU walltime: 0.004ms
Draw calls GPU elapsed time: 0.142ms
inst_div
One last experiment. I hacked that one together pretty much as my brother was starting to run the benchmarks on various machines. :D
Anyway, its mostly the same code as one_ssbo_ext_one_sdf but the data is not read from an SSBO but instead fed into the vertex shader via vertex attributes and instancing. Back to the "classic" OpenGL style. The idea is to have two vertex buffers: A small one with just 6 vertices (1 rectangle) and a larger one with per-rectangle data. The small vertex buffer is then draw with instancing, one instance per rectangle. The larger vertex buffer is setup in the VAO to advance by 1 for each instance (aka an instance divisor of 1). This lets the OpenGL driver generate the buffer decoding shader code, which is hopefully more optimized than my stuff. The API functions to setup the VAO (what stuff in the buffers goes into what vertex shader attribute) can be a bit confusing but the Direct State Access API makes that tolerable.
Turns out the Intel Arc A770 really likes it. The GPU time goes down to 0.34x of one_ssbo_ext_one_sdf. On the GTX 1080 it's 0.67x. For the rest it's pretty much the same as one_ssbo_ext_one_sdf.
I'll probably use that approach in the end, even if it's less "modern". Simply because I don't have to write the whole bit unpacking stuff in the vertex shader and the VAO setup isn't that bad. At least as long as I use nice round types like 16 bit signed int coordinates. If I need to pack the data a bit tighter (e.g. 12 bit per coordinate) it's back to SSBOs and manual unpacking.
Quirks and closing remarks
I got sidetracked for way to long on this thing. But I guess it's nice to know how SSBOs and classical vertex attributes stack up against each other. Spoiler: It doesn't matter for this workload, use whatever floats your boat.
Another interesting aside was the difference between Linux and Windows OpenGL drivers. I'm using Linux and Windows on my Radeon RX 480 PC in a dual boot configuration (Linux for productive things, Windows for games or fooling around with the WinAPI… which is also like playing games). The result charts contain the benchmark on Linux and Windows, directly next to each other. So there's a direct comparison there. Some years ago the open source Mesa drivers had the reputation of being relatively slow. Doesn't look like it. They're basically just as fast as the Windows driver on my machine. Except for the 1rect_1draw approach. All that API overhead takes almost 3x as long on Linux. The benchmark also consumes a lot less CPU time on Linux but I have no idea what part of that is the OpenGL driver, window manager, just a more optimized printf() function or whatever.
During development I also looked at tooling. I've been using RenderDoc for a few years now and is pretty nice but it can't really tell you why a shader is slow. The Radeon GPU Profiler looks pretty neat, especially those instruction timings, but it only supports Vulkan and DirectX 12. If anyone knows such an shader instruction timing tool for OpenGL 4.5 please let me know. On the other hand that might be a reason to rewrite the thing in Vulkan in a few years.
I've omitted a lot of detail (like the different CPUs), but the post is already too long as it is. In case you have any questions feel free to drop a comment or send me a mail.
If you read the whole thing until here, color me impressed. Take a cookie, you deserve it. ;)